
Procyon® AI 文本生成基准测试 
提示 7(RAG 查询):基准测试如何帮助我们公司节省时间和成本?如何选择用于 RFP 的参考基准测试分数?概述如何高效地测试企业 IT 专用 PC 的性能。根据所提供的背景信息回答。
结果与见解
借鉴了行业领导者的意见进行构建
- 借鉴了领先 AI 供应商的意见进行构建,以充分利用下一代本地 AI 加速器硬件。
- 7 个提示,均模拟多个实际用例,包含 RAG(检索增强生成)和非 RAG 查询
- 能够运行一致、重复的工作负载,最大程度减少常见的 AI 大语言模型工作负载变量。
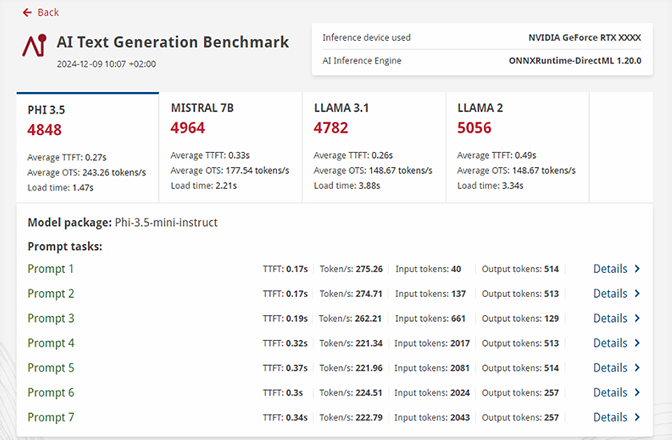
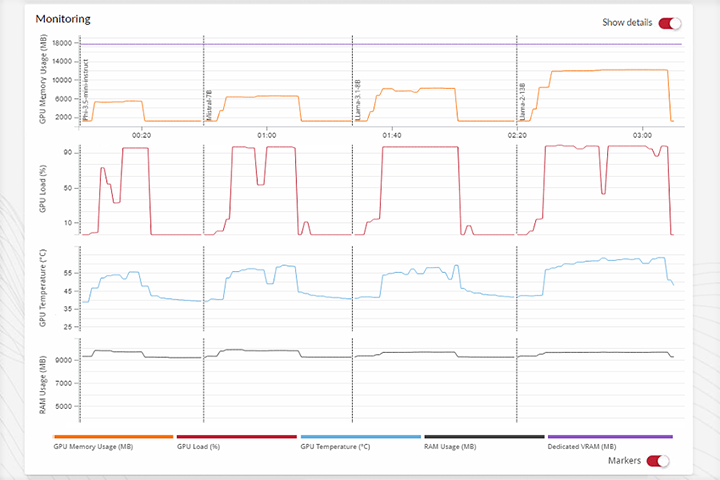
详细结果
- 获取深入的报告,了解系统资源在 AI 工作负载运行期间的使用情况。
- 与测试整个 AI 模型相比,减少了安装规模。
- 轻松比较不同设备的结果,以帮助确定最适合具体用例的系统。
简化 AI 测试
- 方便快捷地使用参数大小各不相同的 4 种行业标准 AI 模型进行测试。
- 实时查看在基准测试期间生成的响应
- 一键式操作,轻松使用所有受支持的推理引擎进行测试;您也可以根据自己的偏好进行配置。
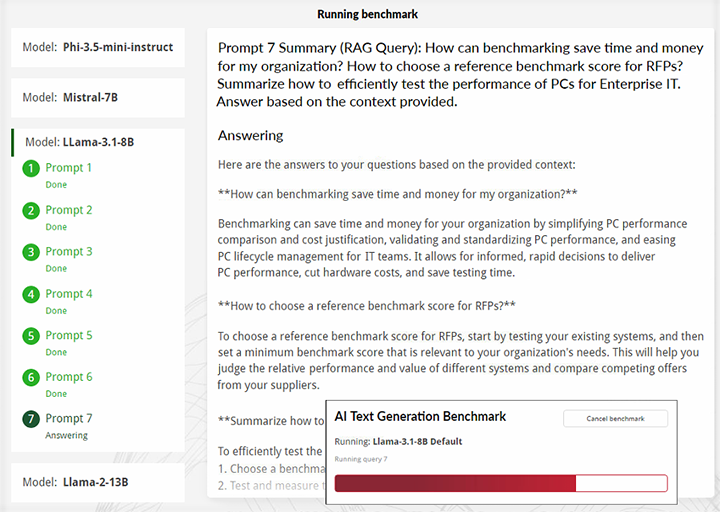
与行业专家共同开发
Procyon 基准测试专为工业、企业和新闻行业使用而设计,具有专为专业用户而开发的测试与功能。Procyon AI 文本生成基准测试是通过 UL 基准测试开发计划 (BDP) 与行业合作伙伴共同设计和开发的。BDP 是 UL Solutions 制订的计划,旨在通过与计划成员的密切合作,创建相关的、公正的基准测试。
推理引擎性能
运用 Procyon AI 文本生成基准测试,可以通过基于 AI 图像生成大负荷工作负载的测试来测量专用 AI 处理硬件的性能,并核实推理引擎的实施质量。
专为专业人士而设计
对于需要使用独立的标准化工具对推理引擎实施及专用硬件的常规 AI 性能进行评估的工程团队,我们开发了 Procyon AI 推理基准测试。
快速并且容易使用
基准测试易于安装和执行,无需复杂的配置。使用 Procyon 应用或通过命令行运行基准测试。查看基准测试分数与图表,或导出详细的结果文件以供进一步分析。
系统要求
所有 ONNX 模型
存储空间:18.25 GB
所有 OpenVINO 模型
存储空间:15.45 GB
Phi-3.5-mini
ONNX(含 DirectML)
- 6GB VRAM(独立 GPU)
- 16GB 系统 RAM (iGPU)
- 存储空间:2.15 GB
Intel OpenVINO
- 4GB VRAM(独立 GPU)
- 16GB 系统 RAM (iGPU)
- 存储空间:1.84 GB
Llama-3.1-8B
ONNX(含 DirectML)
- 8GB VRAM(独立 GPU)
- 32GB 系统 RAM (iGPU)
- 存储空间:5.37 GB
Intel OpenVINO
- 8GB VRAM(独立 GPU)
- 32GB 系统 RAM (iGPU)
- 存储空间:3.88 GB
Mistral-7B
ONNX(含 DirectML)
- 8GB VRAM(独立 GPU)
- 32GB 系统 RAM (iGPU)
- 存储空间:3.69 GB
Intel OpenVINO
- 8GB VRAM(独立 GPU)
- 32GB 系统 RAM (iGPU)
- 存储空间:3.48 GB
Llama-2-13B
ONNX(含 DirectML)
- 12GB VRAM(独立 GPU)
- 32GB 系统 RAM (iGPU)
- 存储空间:7.04 GB
Intel OpenVINO
- 10GB VRAM(独立 GPU)
- 32GB 系统 RAM (iGPU)
- 存储空间:6.25 GB